Vale. Hace ya mucho tiempo que no escribo… y la razón es porque el trabajo ha estado terrible… Principalmente porque me movieron a un proyecto y estoy como fullStack React/NodeJS y aún soy junior en esta tecnología/lenguaje.
Respecto al post, el mundo front me quedó gustando 😀 Si han visto mis post anteriores, siempre desarrollé aplicaciones con metodologías de hace ya 20 años y esto de frontEnd/backEnd me quedó gustando.
Es por ello que ahora para mis proyectos personales estoy usando cada vez menos PHP. Lo utilizo con un único cliente (y por petición del cliente).
Ahora escribo únicamente en JavaScript, utilizando NextJS (v13)y con esto ya quedo fullStack.
Ok, volvamos al tema.
Estaba tratando de configurar el DatePicker de MUI con Formik… y no había forma de hacerlos funcionar. O no supe buscar.
Y tiene pinta de funcionar … pero al momento de seleccionar una fecha pasaba esto:
Y esto qué significa!
Luego de ir a Google y encontrar a alguien con el mismo problema. En resumen, DatePicker espera un string para iniciar (porque, además, siempre devuelve un string), pero si estás tipando los datos en Formik (para validarlos) como Date, entonces es incompatible uno con otro. La solución? Transformar el Date (que en realidad es un number) a String.
Para aprender/practicar, estaba creando una aplicación únicamente usando React y las herramientas de Firebase (en su versión «gratis»).
Logré crear usuarios y unos cuantos documentos simples. Todo relativamente simple.
El problema comenzó cuando necesité realizar una acción algo «compleja» para React (manteniendo el foco en lo «Front») relacionada con obtener ciertas colecciones utilizando distintos documentos… y ahí Google me dijo que si quería ponerme creativo, necesitaba pasar por caja. Osviamente dije que no.
Así que, mi aplicación ahora necesitaba un Backend… pero recordé lo mucho que sufrí creando la parte de autenticar usuarios. Ahí fue cuando pensé:
Y si utilizo firebase para manejar los usuarios de sistema? No debería tener problemas en «conectar» firebase con Nest.JS… o si?
Y si, se puede. Encontré 3 distintas partes y junté todo para finalmente quedarme con lo siguiente.
Paso 1: Crear aplicación Nest.JS
Creamos la aplicación, instalamos las primeras dependencias y las que necesitaremos:
Con nuestra aplicación base, creamos la carpeta «auth» bajo src. Dentro creamos el archivo auth.strategy.ts para definir nuestra estrategia para manejar el token:
Como estamos trabajando con Passport, necesitamos la clave para verificar el token. Lo relevante aquí es tener presente secretOrKey. En el siguiente paso lo rellenaremos.
Paso 2: Obtener el token y encontrar nuestra SecretKey
Ok entonces necesitamos comenzar con una aplicación lista y funcionando en Firebase, puntualmente la autenticación. Creamos un usuario y nos quedamos con el token.
Si bien la creación de usuarios podríamos realizarla en NestJS, en mi caso la mantendré en la parte Front. De esta forma, y una vez creado un usuario, nos quedamos con el token que nos entregue Firebase. O hacemos el login desde nuestra aplicación que ya esté utilizando Firebase.
Tenemos nuestro Token? Perfecto, ahora abrimos una pestaña nueva, vamos a jwt.io, pegamos nuestro token y nos fijamos en el campo kid del header.
Con ese valor, ahora ingresamos en las claves públicas que entrega Google para verificar los token. Copiamos todo lo que corresponda en el kid que nos corresponda:
Y eso ya lo pegamos en el campo secretOrKey que dejamos en blanco.
Paso 3: Editar nuestra Nest.js App
Ahora volvemos al app.module.ts e injectamos nuestra estrategia bajo providers:
import { Module } from '@nestjs/common';
import { AppController } from './app.controller';
import { AppService } from './app.service';
import { ProductsModule } from './products/products.module';
import { AuthStrategy } from './auth/auth.strategy';
@Module({
imports: [ProductsModule],
controllers: [AppController],
providers: [AppService, AuthStrategy],
})
export class AppModule {}
Por último, editamos app.controller.ts. En nuestra ruta pública (/) únicamente agregamos un console.log para ver qué trae el request. En la ruta nueva (/private) agregamos la lectura de token y el mismo console.log.
Al entrar en la ruta pública, tendremos la respuesta sin necesidad de un token. Obviamente console.log mostrará un undefined ya que no existe usuario, pero podremos utilizar el recurso.
Si intentamos acceder al endpoint privado, sin enviar un token (o uno incorrecto), tendremos un:
{
"statusCode": 401,
"message": "Unauthorized"
}
Pero si el token es válido:
Y con esto ya podemos seguir trabajando sin problemas 😀
Para entrar aquí, no usamos admin. Usamos el email que definimos en PGADMIN_DEFAULT_EMAIL.
Personalmente, estuve dando bote porque pensé que era el usuario y clave definido en POSTGRES_USER….
Una vez dentro, para agregar al servidor:
Recordemos que son 2 imágenes separadas, por lo que si escribimos localhost, en realidad estaremos buscando el localhost dentro del container de PgAdmin.
Otra entrada, otra tecnología, otro Gestor de Base de datos.
Trabajo con Intellij IDEA y tocaba pagar el año. Vivo en Chile y, por la pésima gestión, el dólar está por las nubes. Mucho más que en otros países de LatinoAmérica.
De modo que aproveché de aprender una nueva tecnología… que fuera más «barata» de usar jaja.
Entonces, buscando en Google sobre Frameworks para NodeJS, llegué a Nest. Está basado en Express, pero con mejoras.
No entraré en detalles porque en su gran mayoría no los entiendo… pero me gustó que utilizara TypeScript y que todo se maneje en forma de módulos. Además, tienen muchas librerías adaptadas.
TypeScript porque es un «lenguaje» que no manejo y los módulos por el orden de archivos que debes seguir. Nest en cierta forma obliga la metodología SOLID. De modo que cada acción debe ir en su propio archivo. Ya lo veremos.
En este tutorial, armaremos una REST API para una único esquema. Sin embargo, NestJS puede responder con vistas, si así lo deseamos.
Manos a la obra
Instalamos global con
npm i -g @nestjs/cli
Y generamos el proyecto con
nest new project-name
Listo, tenemos los archivos necesarios. Se entiende qué hace cada uno, pero desglosemos:
Los archivos comienzan siempre por el nombre del módulo al que correspondan. En este caso, corresponden al módulo app. App es siempre el módulo inicial. Sabemos que es el inicial porque está directamente bajo src.
Los archivos .spec.ts son para pruebas. Se generan automáticamente y siempre relacionados a otro archivo. En este caso, app.controller.spect.ts se encarga de testear los endpoint de nuestro controller.
Siguiendo con el controller, tiene asociado un Servicio (AppService), el cual se encargará de responder el endpoint correspondiente. Es necesario agregar la anotación de @Controller() para que NestJS lo maneje como tal.
import { Controller, Get } from '@nestjs/common';
import { AppService } from './app.service';
@Controller()
export class AppController {
constructor(private readonly appService: AppService) {}
@Get()
getHello(): string {
return this.appService.getHello();
}
}
Nuestra ruta @Get() simplemente responderá el «/» inicial, ya que no tiene parámetros.
Ojo que la función solamente devuelve un string. Estamos en TypeScript.
Saltemos app.module. Veamos AppService.
import { Injectable } from '@nestjs/common';
@Injectable()
export class AppService {
getHello(): string {
return 'Hello World!';
}
}
La anotación @Injectable(), como su nombre indica, marca esta clase (AppService) para que sea instanciada en algún otra parte. Esa otra parte, como ya vimos, fue el Controller.
Y luego ya podemos definir las funciones que necesitemos.
Ahora veamos app.module. Como ya mencioné, NestJS funciona en módulos. Un módulo tiene X cantidad de archivos, que pueden reutilizarse en algún otro módulo, dependiendo de nuestras necesidades. De esta forma, cada módulo tiene un archivo que define los elementos que utilizará, y los que podrán utilizarse en otro módulo.
import { Module } from '@nestjs/common';
import { AppController } from './app.controller';
import { AppService } from './app.service';
@Module({
imports: [],
controllers: [AppController],
providers: [AppService],
})
export class AppModule {}
Entonces, agregamos la anotación de @Module. Podemos definir 4 elementos que usaremos:
imports: «Cosas» que usaremos
controllers: los endpoints que usaremos
providers: un provider es «algo» que podemos inyectar en algún elemento. En este caso: AppService, que inyectaremos en AppController.
exports: «Cosas» que podrán utilizar otros módulos. En este caso, como estamos en el módulo principal (App) exportaremos nada.
Por último main.ts. Simplemente define cómo iniciaremos nuestro servidor. En este caso, únicamente definiendo el módulo inicial (AppModule) y el puerto.
import { NestFactory } from '@nestjs/core';
import { AppModule } from './app.module';
async function bootstrap() {
const app = await NestFactory.create(AppModule);
await app.listen(3000);
}
bootstrap();
Buen trabajo, con esto ya tenemos una noción de trabajo.
Ahora agreguemos MongoDB y juguemos con una API funcional. Algo que solamente guarde un único dato. Algo simple.
Comenzaremos creando un nuevo módulo. Si bien existe un comando para hacerlo automágicamente, lo haremos a mano para entender todo.
Entonces, creamos la carpeta nueva bajo src. En mi caso, se llamará mantenedor. Dentro, creamos las carpetas: controllers, dto, schemas, services. Y el archivo mandenedor.module.ts.
Schema
Comenzamos por schemas. Un esquema es la representación de una colección bajo MongoDB. Obviamente podemos tener más de uno, pero por ahora, crearemos el archivo persona.schema.ts.
import { Prop, Schema, SchemaFactory} from "@nestjs/mongoose";
import { Document } from "mongoose";
export type PersonaDocument = Persona & Document;
@Schema()
export class Persona {
@Prop({ required: true})
nombre: string;
}
export const PersonaSchema = SchemaFactory.createForClass(Persona);
Aquí definimos 3 «cosas».
El tipo PersonaDocument, que será de tipo Persona y Document al mismo tiempo. Podemos compararlo a los @Repository de SpringBoot, ya que al comportarse como Document, tenemos acceso a las acciones de save(), findAll(), delete(), etc.
La clase Persona, que está anotada como Schema(). Esta clase tiene la propiedad nombre, obligatoria, de tipo string. Persona es el tipo de dato en sí. En MongoDB, el Id se crea automáticamente. Podríamos agregarlo a mano, pero eso significaría generar nuestra propia lógica.
Por último, PersonaSchema. Esto lo usaremos para relacionar la clase propiamente tal con la colección en MongoDB. Persona fue definido usando las características y sintaxis de NestJS. Al llamar a SchemaFactory.createForClass, transformamos la clase de tipo NestJS a una que Mongooseentienda.
dto
Como indica el nombre, usaremos esto para transferir data desde el cliente al servidor. De modo que la estructura a seguir, la definimos aquí. crearPersona.dto.ts:
import { IsNotEmpty } from "class-validator";
export class CrearPersonaDto {
@IsNotEmpty({
message: 'El nombre no puede estar vacío',
})
readonly nombre: string;
}
Solamente marcamos el nombre como un campo que no puede estar vacío.
Service
Como indica el nombre, aquí realizamos las acciones propiamente tal. Como es un ejemplo, no definimos lógica. Pero cada lógica de negocio relacionada a cada acción, irá en este archivo persona.service.ts.
import {Model} from 'mongoose';
import {Injectable} from "@nestjs/common";
import {InjectModel} from "@nestjs/mongoose";
import {Persona, PersonaDocument} from "../schemas/persona.schema";
import {CrearPersonaDTO} from "../dto/crearPersona.dto";
@Injectable()
export class PersonaService {
constructor(
@InjectModel(Persona.name)
private personaModel: Model<PersonaDocument>,
) { }
async create(crearPersonaDTO: CrearPersonaDTO): Promise<Persona> {
const porCrear = new this.personaModel(crearPersonaDTO);
return porCrear.save();
}
async delete(personaId): Promise<Persona> {
return this.personaModel.findByIdAndDelete(personaID);
}
async findAll(): Promise<Persona[]> {
return this.personaModel.find().exec();
}
async get(personaId): Promise<Persona> {
return await this.personaModel.findById(personaID).exec();
}
}
Importante aquí es notar el constructor. Indicamos que injectaremos el modelo Persona. name no hace referencia a algún atributo en especial, sino al nombre del archivo. Lo que sea que injectemos, lo manejaremos en la variable personaModel, la cual es del tipo Model<PersonaDocument>. Recordemos que tanto Persona como PersonaDocument fue definido en el paso de schema.
Lo otro importante, es fijarse en el parámetro de la función create.
Por último, notar que las funciones son asíncronas y devuelven Promesas. Esto porque la conexión a Mongo toma tiempo.
Controller
Llegamos a persona.controller.ts. Aquí definimos cada endpoint
import {Body, Controller, Delete, Get, NotFoundException, Post, Query} from '@nestjs/common';
import { PersonaService } from "../services/persona.service";
import { CrearPersonaDto } from "../dto/crearPersona.dto";
import { ValidateObjectId } from "../../shared/pipes/validate-object-id.pipes";
@Controller('persona')
export class PersonaController {
constructor(private readonly personaService: PersonaService) { }
@Get()
async findAll(){
return this.personaService.findAll();
}
@Post()
async add(@Body() crearPersonaDTO: CrearPersonaDto){
return await this.personaService.create(crearPersonaDTO);
}
@Delete()
async delete(@Query('personaId', new ValidateObjectId()) personaId){
const deletedPersona = await this.personaService.delete(personaId);
if (!deletedPersona) throw new NotFoundException('Persona no existe!');
return {
mensaje: 'Persona eliminada!',
unidad: deletedPersona,
}
}
}
ValidateObjectID lo veremos en unos instantes.
Con @Controller(‘persona’) definimos que nuestra clase será un controller. Además de marcar el inicio de cada enpoint como persona. De esta forma, para acceder a nuestro controller tendremos: http://localhost/persona.
En el constructor definimos nuestro objeto para servicios.
Notar que cada endpoint no tiene un tipo de respuesta. Esto porque NestJS se encarga de ello, en base a la respuesta que defina cada función en nuestro servicio.
En nuestra función add (POST /persona) tomaremos lo que venga como cuerpo en la petición y lo tomaremos como el DTO que definimos.
En DELETE /persona usaremos el parámetro de entrada personaId. Luego lo validaremos. Esa validación la definimos en el archivo indicado al inicio. Tiene esta estructura:
import { PipeTransform, Injectable, ArgumentMetadata, BadRequestException } from "@nestjs/common";
import * as mongoose from "mongoose";
@Injectable()
export class ValidateObjectId implements PipeTransform<String> {
async transform(value: string, metadata: ArgumentMetadata){
const isValid = mongoose.Types.ObjectId.isValid(value);
if(!isValid) throw new BadRequestException('Invalid ID!');
return value;
}
}
Como vemos, también está marcado como Injectable.
Archivo module
Para terminar, relacionamos todo en nuestro archivo mantenedor.module.ts:
import { Module } from '@nestjs/common';
import { MongooseModule } from "@nestjs/mongoose";
import { PersonaService } from "./services/persona.service";
import { PersonaController } from "./controllers/persona.controller";
import { Persona, PersonaSchema } from "./schemas/persona.schema";
@Module({
imports: [
MongooseModule
.forFeature([
{ name: Persona.name, schema: PersonaSchema }
])
],
controllers: [ UnidadMaterialController ],
providers: [ UnidadMaterialService ]
}) export class MantenedorModule {}
Entonces, para que este módulo funcione, importará el Módulo de Mongoose. De él, asociaremos el Schema de Persona (MongoDB), con el Modelo Persona (nuestra clase Persona).
Para que nuestro módulo inicial (AppModule) pueda utilizar este módulo (MantenedorModule) y podamos conectarnos a MongoDB, actualizaremos el archivo app.module.ts:
import { Module } from '@nestjs/common';
import { MongooseModule } from "@nestjs/mongoose";
import { AppController } from './app.controller';
import { AppService } from './app.service';
import { MantenedorModule } from "./mantenedor/mandenedor.module";
import { RouterModule } from "@nestjs/core";
import { MONGO_URI } from "./shared/constant/settings";
@Module({
imports: [
MantenedorModule,
RouterModule.register([
{
path: 'mantenedor',
module: MantenedorModule,
}
]),
MongooseModule.forRoot(MONGO_URI),
],
controllers: [AppController],
providers: [AppService],
})
export class AppModule {}
Entonces lo que cambió está en los imports:
Necesitamos el MantenedorModule.
Agregamos un path extra para todos los endpoint dentro del controller del módulo. En este caso, agregamos mantenedor. De esta forma, ya no entraremos por /persona, si no que ahora será /mantenedor/persona.
Necesitamos el MongooseModule, donde agregamos la conexión indicando una URI. En este caso, lo guardamos un archivo con constantes. Solamente tiene :
Listo! Ahora podemos probar. En mi caso, MongDB lo tengo en un Docker. Vamos a
Postman
Tenemos nada, así que agreguemos algo
MongoDB creó un propio _id y además el registro de ediciones. En este caso 0, porque es «nuevo».
Volvamos a listar
Por último, eliminemos algún registro. Utilizamos la ruta
http://localhost:3000/mantenedor/persona
Tomamos el ID del registro a eliminar, y lo dejamos en el el parámetro personaId. Para generar un error, usemos un ID que no exista.
Ahora, cambiemos el nombre del parámetro:
Esto porque el controller está esperando un parámetro llamado personaId. Al no encontrarlo, envía un undefined. Y esto, no pasa por el validador. Es un Id inválido… si… pero el error no es del todo correcto.
NestJS nos permite crear decoradores. En este caso, no usaríamos @Query() quien no permite validar si viene o no algún parámetro.
Si se dieron cuenta, tengo una carpeta shaded. En ella dejé el archivo de constantes, el archivo pipe para validar el ID, y ahora el decorador para validar parámetros.
Y por código, tendremos:
import { createParamDecorator, ExecutionContext, BadRequestException } from "@nestjs/common";
export const QueryRequired = createParamDecorator(
(key: string, ctx: ExecutionContext) => {
const request = ctx.switchToHttp().getRequest();
const value = request.query[key];
if ( value === undefined ) {
throw new BadRequestException(`Parámetro ${key} no se encuentra!`)
}
return value;
}
);
Editamos el controller, volvemos a probar:
Perfecto. Ahora usen la variable que corresponde, con un Id que exista.
Listo! Buen trabajo!
Tenemos nuestra API funcionando.
Para que sea más completa podríamos agregarle elementos para Swagger, pero eso lo veremos en otra oportunidad.
Terminando, comentar que estuve casi 2 días recopilando información… pero para eso el post, para que alguien más no tenga problemas al iniciar 😉
Llevo más de 10 años como programador. En mis comienzos (año 2010) me gustaba aprender de todo… Y con el tiempo comencé a trabajar en una empresa chica y me atasqué. Particularmente, con php y vainillaJS.
Por 8 años. Porque no necesitaba más. Problema que tenían los usuarios los solucionaba con lo anterior. Estaba cómodo así, respondía a tiempo y el usuario era feliz. ¿Para qué cambiar?
Y luego llegué a una empresa grande de informática. Grande digamos sexta a nivel mundial.
Volví a programar en Java, aprendí Spring boot. Tuve que aprender React para un proyecto. Manejar la «agilidad», acostumbrarme a las nuevas formas de trabajo.
Era un cavernícola que viajó en el tiempo al año 2022.
Dentro de todo, aprendí Docker. Y vaya que cambió mi vida.
Para ponernos en contexto, unas pequeñas vivencias:
Un día X estaba trabajando en una aplicación que usaba java 17 y al subirla al servidor… no funcionaba. El típico: pero si en mi equipo funciona! Corté por lo sano y formateé el servidor desde 0, instalando MI versión de java.
Otra vez, tuve que viajar a una zona con mala señal de red y la bd de pruebas estaba en la nube (mysql). Trabajo con un Mac y me fue imposible instalar mysql local. Terminé cambiando el proyecto a PostgreSQL.
Una última: creando una app en Spring boot que usaba redis y postgresql… y no tenía instalado ni postgresql ni redis. Así que no podía levantar la app.
¿Qué tienen en común estas 3 historias? Que si hubiera conocido antes Docker, este problema no lo tendría… Veamos porqué
Bueno y qué es Docker?
Resumiendo, es un ambiente donde puedes tener múltiples «máquinas virtuales» de «programas». Quiero decir, una máquina virtual tiene un sistema operativo y sobre él instalas los programas que quieras. Esto significa que tomarás recursos de tu máquina «real» para que sean utilizados por la máquina virtual.
Con una «máquina virtual» de Docker, necesitas lo mínimo para funcionar, además del «programa» que necesites. Me refiero, por ejemplo: una máquina que únicamente tenga PostgreSQL y otra sólo con Redis.
Y como son «máquinas virtuales», puedes apagarlas cuando quieras jugar lolcito 😀
Manos a la obra
Actualmente estoy trabajando en una app escrita en Java (Spring boot) y utiliza PostgreSQL.
Obviamente, lo primero es instalar Docker. En mi caso, tengo un Mac M1, así que descargué dicha versión. La instalación no tiene dificultad.
Spring Boot
El único cambio a mi app fue dónde apuntar para el servidor de BD. Editando application.properties
Importante identificar el nombre de la máquina, la BD, el usuario y la password.
Creando archivos Docker
Aquí tenemos que definir las imágenes y los contenedores. En palabras simples, las imágenes son Clases y los contenedores objetos.
De modo que puedo tener una imagen de PostgreSQL, pero 2 ó más contenedores (2 ó más servidores distintos, cada uno con sus datos).
Imagen App Spring Boot
Para crear una imagen, creamos un archivo con nombre Dockerfile en nuestra raíz de proyecto. Ojo que no tiene extensión. Este archivo tendrá todas las instrucciones para crear la imagen. Entonces en mi caso:
FROM define la imagen base que usaremos. Saltemos el –platform=linux/x86_64 por un segundo. La imagen que definimos aquí puede ser un gestor de BD, un «lenguaje», etc. En este caso, eclipse-temurin es el proyecto que reemplaza a openJDK. Si a la imagen le agregamos :, quiere decir que queremos una versión en específico. Aquí la versión de Java 17, en linux alpine.
Para obtener o buscar imágenes podemos buscarlas en hub.docker.com
Volvamos al –platform. Esto es porque, por defecto, Docker busca la imagen que corresponda a nuestro ambiente. En mi caso amd64… y como esa imagen en particular no existe, debo usar la «versión» para linux. Lamentablemente, tengo que emular y afecta en el rendimiento de este contenedor.
LABEL se utiliza para escribir cualquier metadato que nosotros queramos.
VOLUME define la carpeta en la que se ejecutará nuestra aplicación dentro del contenedor (o la máquina virtual linux alpine)
EXPOSE para «abrir» X puerto.
ADD para copiar el o los archivos desde nuestra máquina al contenedor. En mi caso, como estoy generando un contenedor para mi app spring, muevo un .jar. Notar que la ruta es relativa a la ubicación del archivo Dockerfile.
ENTRYPOINT define la intrucción inicial de nuestro contenedor. O lo que ejecutaremos cada vez que lo iniciemos.
Con este archivo podemos crear nuestra imagen con la app.
Imagen PostgreSQL
Ahora crearemos un archivo, también en la raíz, con el nombre docker-compose.yml. Aquí le decimos a Docker que tendremos 2 contenedores trabajando en conjunto. Tiene la siguiente estructura:
El nombre del container para app será cuanto-cuesta-app. Así, también, se llamará la imagen, que se creará en base al archivo Dockerfile en la ruta raíz (./)
El puerto 8080 en nuestro equipo enviará las peticiones al puerto 8080 del contenedor.
Por último, app dependerá de dbpostgresql. Ojo que dbpostgresql es el nombre de la máquina, lo que definimos en application.properties. De modo que lo que ustedes escojan como nombre, deben definirlo en el nombre del servidor para conectar a la BD.
Pasando a dbpostgresql, tendrá como imagen la versión 14.5 de postgresql, en un linux alpine. Notar que, al no tener el valor build, se descargará la imagen directamente desde hub.docker.com.
El puerto 5432 en nuestro equipo enviará las peticiones al puerto 5432 del contenedor.
Esta imagen en particular, acepta parámetros para su configuración. En este caso, la password del super usuario. Este parámetro es obligatorio.
Si definimos un usuario, éste será el super usuario. Si no lo definimos, se creará root.
Por último, la base de datos inicial a crear.
Generar todo
Ok, ahora que tenemos todo configurado, compilamos la aplicación. En mi caso, queda en la carpeta que definí en Dockerfile.
Y luego solamente ejecuto
docker-compose up --build
Esto creará la imagen de mi app Spring boot. Luego descargará la imagen de PostgreSQL. Y finalmente «instanciará» las imágenes en cada contenedor, los cuales estarán «unidos». De todas formas, el contenedor de PostgreSQL puede recibir llamadas desde cualquier cliente en nuestra red (siempre y cuando abramos el puerto en nuestra máquina «física»).
Imágenes
Contenedores
Como pueden ver, ambos contenedores están agrupados, tomando como nombre la carpeta donde estaba Dockerfile.
Además, pueden notar que el container de Java tiene una etiqueta indicando que puede fallar o tener un bajo rendimiento por ser una emulación.
Y listo! Ya puedo utilizar mi aplicación desde un ambiente virtualizado.
Cuando quiera realizar alguna actualización al código, simplemente ejecuto nuevamente el comando de docker-compose.
Otra de esas entradas para mi, pero que puede servirle a alguien.
En las «cosas» que había escrito en SpringBoot, hasta ahora, no necesité crear usuarios ni darle permisos a estos.
Leyendo por aquí y por allá, logré agregarle un login y permisos a ciertas acciones.
Ok, lo primero es agregar la dependencia para el manejo de usuario. En Initializr lo encontramos por Spring Security. Ya sea por Gradle o Maven: ‘org.springframework.boot:spring-boot-starter-security’.
Recargamos y listoco.
Modelo
Ahora seguimos con la clase para nuestro usuario, y otra para los roles. En este tuto, y básicamente porque en mi caso no necesito más, manejaré un rol por usuario. No más. Quiero decir, el usuario será Administrador o Miembro. No tendrá más de un rol.
De esta forma, la clase miembro quedaría:
@Entity
@Table(name = "usuario", uniqueConstraints = @UniqueConstraint(columnNames = "nombre"))
public class UsuarioModel {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
@Column(name = "id", nullable = false)
private Long id;
@Column(name = "nombre")
private String nombre;
private String password;
@ManyToOne
public RolModel rol;
}
Importante destacar que la columna nombre será única. Y que el rol quede marcado @ManyToOne (un rol -> muchos usuarios). Agregamos los getters/setter/constructores y eso sería.
Respecto a la clase Rol:
@Entity
@Table(name = "rol")
public class RolModel {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long id;
private String nombre;
@OneToMany(cascade = CascadeType.ALL)
@JoinColumn(name="rol_id")
private Set<UsuarioModel> usuarios;
}
Aquí es donde definimos la relación desde usuario. De esta forma, la tabla usuario queda como:
create table usuario
(
id bigserial
primary key,
nombre varchar(255)
constraint ukcto7dkti4t38iq8r4cqesbd8k
unique,
password varchar(255),
rol_id bigint
constraint fkshkwj12wg6vkm6iuwhvcfpct8
references rol
);
alter table usuario
owner to montesanto;
Ojo que es el código que genera Hibernate. Además, estoy usando PostgreSQL.
Repositorio
Aquí es nada de otro mundo. Simplemente:
@Repository
public interface UsuarioRepository extends CrudRepository<UsuarioModel, Long> {
public UsuarioModel findByNombre(String nombre);
}
Y podemos definir todas las funciones extras que necesitemos.
Servicio
Aquí cambia un poco, básicamente porque dividimos el servicio para Usuario en 2. Esto porque nuestro servicio tendrá que heredar funciones de la clase org.springframework.security.core.userdetails.UserDetailsService
UsuarioService
public interface UsuarioService extends UserDetailsService { }
Ojo que no está marcada como Servicio. Eso queda para la próxima clase. Podríamos definir las típicas funciones de guardar, o listar. O las podríamos dejar en la implementación de esta clase. Al menos yo lo dejé así (en la clase que implementa) para no escribir 2 veces, aunque puede no ser ordenado.
UsuarioServiceImpl
Esta clase es larga, así que iremos por parte.
La definimos como:
@Service
public class UsuarioServiceImpl implements UsuarioService{
private final UsuarioRepository usuarioRepository;
public UsuarioServiceImpl(UsuarioRepository usuarioRepository){
this.usuarioRepository = usuarioRepository;
}
}
Aquí mismo agregamos el método para registrar nuevos usuarios:
public void guardar(UsuarioModel usuarioModel){
BCryptPasswordEncoder passwordEncoder = new BCryptPasswordEncoder();
usuarioModel.setPassword(passwordEncoder.encode(usuarioModel.getPassword()));
usuarioRepository.save(usuarioModel);
}
Lo relevante aquí es la clave. Usamos la clase org.springframework.security.crypto.bcrypt.BCryptPasswordEncoder para encriptarla.
Respecto al login y acceso en general, es obligatorio agregar el siguiente método:
@Override
public UserDetails loadUserByUsername(String nombre) throws UsernameNotFoundException {
UsuarioModel usuarioModel = usuarioRepository.findByNombre(nombre);
if(usuarioModel == null){
System.out.println("Usuario o password incorrectos");
throw new UsernameNotFoundException("Usuario o password incorrectos");
}
return new User(usuarioModel.getNombre(), usuarioModel.getPassword(), mapearAutoridadesRoles(usuarioModel.getRol()));
}
Este método lo utiliza automágicamente Spring al loguear un usuario. Lo importante es notar que devuelve un org.springframework.security.core.userdetails.User. El constructor de dicha clase necesita un nombre de usuario, una contraseña (contraseña que ya quedó encriptada en BD) y un arreglo con todos los roles que tenga el usuario.
Como ya dije, en mi caso únicamente tengo (o al menos por ahora) un único rol por usuario, pero como necesito un listado, lo dejé así para transformar más fácil:
Es como cualquier otro… Tal vez lo único relevante es que al momento de registrar un usuario, agregué el rol a «mano». Ya que los administradores los fijaré yo mismo por BD.
@Controller
public class UsuarioController {
@Autowired
UsuarioServiceImpl usuarioService;
@PostMapping(value = "/Usuario/Nuevo")
public String nuevo(@Valid @ModelAttribute("formData") UsuarioFormData formData,
BindingResult binding,
Model model){
if(binding.hasErrors()){
return "usuarios/nuevo";
}
try {
UsuarioModel usuario = formData.toModel();
usuario.setRol(new RolModel(2L,"Miembro"));
usuarioService.guardar(usuario);
return "redirect:/Usuarios";
} catch (Exception e) {
System.out.println(e.getMessage());
binding.rejectValue("nombre", "error.user", "Nombre de usuario ya existe");
return "usuarios/nuevo";
}
}
}
Clase SecurityConfig
Esta clase se encarga de todo:
@Configuration
@EnableWebSecurity
public class SecurityConfig extends WebSecurityConfigurerAdapter {
@Autowired
private UsuarioService usuarioService;
@Bean
BCryptPasswordEncoder passwordEncoder(){
return new BCryptPasswordEncoder();
}
@Bean
public DaoAuthenticationProvider authenticationProvider(){
DaoAuthenticationProvider auth = new DaoAuthenticationProvider();
auth.setUserDetailsService(usuarioService);
auth.setPasswordEncoder(passwordEncoder());
return auth;
}
@Override
protected void configure(AuthenticationManagerBuilder auth) throws Exception {
auth.authenticationProvider(authenticationProvider());
}
}
Hereda de org.springframework.security.config.annotation.web.configuration.WebSecurityConfigurerAdapter.
Obviamente, necesitamos injectar nuestro servicio (ojo que estamos llamando al «servicio en blanco»)
El primer método se encarga de asociar tanto el método para obtener el usuario (desde BD, en nuestro caso) como fijar la forma en que encriptamos la contraseña (o desencriptamos, en este caso).
Y el segundo lo agrega al adapter.
Esta clase tiene un tercer método que veremos ahora:
Como ven, aquí definimos cuales rutas serán «públicas» y cuáles necesitarán un usuario logueado al sistema.
El método antMatchers() acepta las rutas y luego le agregamos si permitirá o no un acceso. O si lo bloqueará. Y en el caso de bloquear, cuál authority debe tener el miembro.
El orden siempre es decendente. Lo que se defina primero quedará fijo. No es como un css que define el último.
Luego agregamos la ruta del formulario de login, dónde iremos en caso de loguearnos correctamente o dónde ir en caso contrario.
Lo mismo para el logout.
Ahora que lo pienso, hubiese sido mucho más simple agregar las rutas como /admin/Cancion/Nueva, o algo así… en ese caso directamente podría ser .antMatchers(«/admin/**») sin necesidad de marcar todo.
Ok, tenemos todo. Para terminar podemos fijar en Thymeleaf permisos dependiendo de tal o cuál rol tiene cierto usuario.
<div sec:authentication="name">
The value of the "name" property of the authentication object should appear here.
</div>
<div sec:authorize="hasAuthority('Administrador')">
This will only be displayed if authenticated user has auth admin.
</div>
<div sec:authorize="hasAuthority('Miembro')">
This will only be displayed if authenticated user has auth miembro.
</div>
<div sec:authorize="isAuthenticated()">
Text visible only to authenticated users.
</div>
Esta es de esas entradas que hago para mi mismo, pero que pueden servir.
Siempre usé Github para guardar código y ya. Esto a modo personal, ya que en mi antiguo trabajo no usábamos ningún control de versiones… y eso que éramos 3 personas escribiendo código 😀
Ahora que me cambié de trabajo a una empresa de desarrollo «serio», (NTT DATA) aprendí a trabajar con ramas y pull request… cosa que antes nunca necesité.
Aprovechando que me pidieron una actualización para un sistema que hice hace unos años, colgué todo en Github.
Comienzo con un proyecto nuevo y en blanco, más que todo para comenzar desde 0. Agregar, además, que estoy usando Intellij IDEA para todo. Tengo entendido que la versión Community también tiene las herramientas para trabajar con Git. De todas formas, dejaré los comandos por si alguien quiere seguir por consola 😀
Ok, entonces empiezo en Github, creando un repositorio nuevo:
Ok, ahora tengo que descargar (el término oficial es clonar) la carpeta. Github me entrega un link:
Si lo quiero hacer por comando, debo entrar a la carpeta donde dejaré la nueva «carpeta» y luego:
Ahora, Intellij crea sus propios archivos como cualquier IDE. La «gracia» es que Intellij crea un archivo .gitignore y se agrega a si mismo.
El archivo .gitignore lista todo lo que NO quiero compartir. En este caso, las carpetas «personales» de cada programador. Es un simple archivo de texto. En mi caso tiene:
Sin embargo no es suficiente. Esto lo veremos nuevamente. Por ahora, lo dejamos hasta ahí.
Ok, para hacer esto fácil, haremos una página sencilla. El funcionamiento será igual para un par de archivos o para un proyecto gigante.
Listo, eso sería todo.
Entonces, listando los paneles:
A la izquierda tengo todos los archivos del proyecto. La carpeta .idea mantiene todo lo del IDE.
Al medio el código
Un visor
En el panel de la izquierda, tengo archivos en color verde y otro (workspace.xml) en gris/café. Los archivos verdes son archivos «nuevos» para mi proyecto en Github. El archivo gris/café es un archivo que no será parte de mi proyecto.
Ese archivo se ignora porque es listado en el archivo .gitignore. La carpeta .idea también debería ignorarse.
Git (la aplicación, no la «página» Github) agrega archivos al proyecto a pedido. Esto es, cada vez que se utiliza el comando git add. Pero Intellij lo ejecuta cada vez que agregamos un archivo.
El tema es que, la primera vez se ejecuta automágicamente, de modo que la carpeta .idea no se considera. Para que sea ignorada:
Editar el archivo .gitignore y agregar (al menos por ahora): /.idea/
Mover el archivo .gitignore fuera de .idea (dejarlo en raíz).
Limpiar la caché de Git con el siguiente comando: git rm -r –cached . -f
Con esto eliminamos todo lo que está en la caché (-f es un parámetro para forzar el borrado, en el caso que algún comentario no lo permita)
Ahora los colores cambian:
Ok, hasta ahora 0 problemas. Ambos archivos están en color rojo porque no son «parte» del proyecto.
Para agregarlos al proyecto, vamos a la pestaña commit, los marcamos, y luego podemos (o no) escribir un comentario en la caja de texto. Por último click en Commit.
Lo mismo podemos hacer en comando con:
git add index.html .gitignore (o usando git add . para agregar todos los archivos). Esto es el equivalente a marcar los checkbox
git commit -m ‘Esta es la primera carga’
Ok. Tenemos la primera confirmación de código. Esto significa que el código que escribimos llegó a un punto en el que, por ahora, no recibirá modificaciones.
Ahora tenemos que cargarlo a Github. Si nos cambiamos a nuestro repositorio en Github tendremos lo siguiente, ya que aún nuestro repositorio tiene nada:
En Intellij subimos nuestro código con el siguiente botón:
El primero es para descargar cambios desde Github, el segundo para realizar un commit (lo que hicimos antes) y el tercero para cargar los cambios al servidor de Github.
Al clickear el botón, tenemos esta ventana:
Donde tenemos un listado de todos los posibles commits y un detalle de qué archivos fueron agregados, editados o eliminados. Sólo queda dar en push.
En comando, es lo mismo que un:
git push
Volviendo a la página de Github, ahora los archivos están y los podemos ver.
Ya estando ahí, aprovecho de editar el archivo index.html para probar la descarga.
Agregué un h1 en línea 15
Entonces, en el listado de archivos, el que acabo de editar tiene un comentario distinto:
Ahora probemos la descarga con el btn para descargar que vimos anteriormente (o un git pull). Al ser la primera vez nos pregunta si queremos mezclar todo (local contra servidor) o si queremos agregar la actualización como un commit al final de nuestros commits locales. Por ahora iremos con la mezcla.
Y ya tenemos listo nuestro código actualizado. Al trabajar en grupo esto es mucho muy importante, porque aseguramos nuestro trabajo vs el de un compañero.
Para evitar problemas de código (que la misma línea en el programador A diga hola y del programador B diga chao) es que se utilizan ramas.
Hasta ahora hemos trabajado con la rama inicial. Esta rama se llama Master y se crea junto con el repositorio.
Ahora crearemos una rama para realizar cambios a un archivo, en una copia del archivo, que será visible únicamente para nosotros. De esta forma podemos trabajar sin afectar al resto.
Entonces, en Intellij (en la barra inferior):
En comando esto es:
git checkout -b cambioFrutas_x_Animales
Como dice el nombre, cambiaremos el listado desde frutas a Animales. Así:
Ahora el archivo tiene un color azul. Esto es porque el archivo fue editado, respecto al estado anterior.
En la pestaña de commit tenemos, en la cabecera, que el cambio será en la rama nueva:
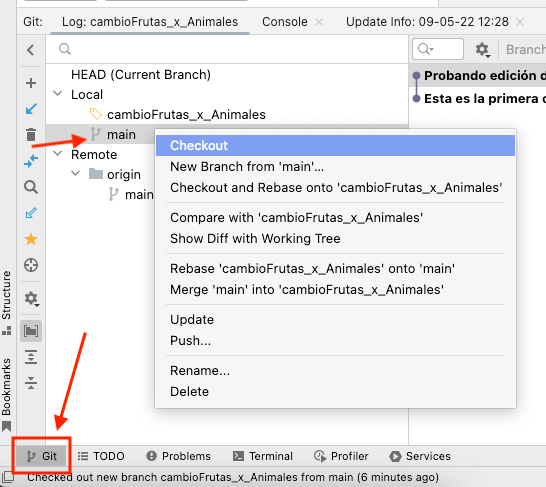
Si quisiéramos volver a la rama principal, en el panel de git (el inferior) tenemos un listado ramas. Click derecho en la que queremos y luego checkout (para cambiar):
Realizamos el commit. Y en el push ahora está yendo directamente a la rama nueva creada.
Al volver a la página de Github, salvo el mensaje, no vemos ningún cambio. Pero tenemos una rama nueva:
Y al dar click ahí podemos ver efectivamente el cambio.
OK, respecto al botón verde. Si lo clickeamos vemos:
Indicando el archivo que está en la rama nueva, vs el archivo en la rama principal.
Este ejemplo es el mejor caso. En el sentido que para «fusionar» ambas ramas no se necesita ningún trabajo adicional. Solamente darle click Create Pull Request, ya que Github no encuentra problemas. Esto lo vemos arriba:
Tenemos como respuesta:
Esto significa que la rama de cambioFrutas puede fusionarse con main. Ahora click en Merge pull request y generamos un commit para la acción:
Si volvemos a la página de inicio, los cambios en el listado ahora se ven en main:
Todo listo en Github.
Y qué pasa en Local ?
Si hacemos un checkout a la rama main en Intellij, aún tenemos el código anterior. Ahora que la rama nueva se fusionó con main en Github (Remote) tenemos que decirle a Local que se actualice.
Cambiamos de rama y luego volvemos a realizar un update (git pull).
Y listo!
Ahora nuestro código en Local, en la rama main, tiene los cambios al día.
Con eso terminamos. Ahora, es algo extraño trabajar de esta forma siendo un equipo de 1, pero para estar ordenado es una buena manera de trabajar. Especialmente para distintos ambientes.
Estoy trabajando en una página para la iglesia donde asisto y cargué una Biblia que encontré en GitHub. Haciendo una prueba de búsqueda, utilicé la palabra cruz. Una típica búsqueda para encontrar todos los versículos (es la mínima expresión en una Biblia) que tuvieran la palabra.
Comencé con un LIKE:
SELECT * FROM versiculo WHERE texto LIKE '%cruz%'
Naturalmente, obtuve resultados que no correspondían:
Y aquí recordé que alguna vez escuché el famoso Full Text Search… así que una rápida búsqueda por Google me trajo aquí.
Leyendo, entendí que el concepto del FTS es más que buscar un conjunto de letras, si no una búsqueda semántica.
Por ejemplo (y siguiendo lo de arriba) podría buscar por la palabra «avisar» y me devolvería el registro que tiene «aviso«. Esto con un like no se podría. Y si bien no es lo que estaba buscando, me llamó tanto la atención que seguí leyendo !! 🤣
Antes que sigamos, aviso que esto es usando PostgreSQL. Me imagino que en MySQL debe poderse, pero tal vez con otras funciones.
Nota aparte, empecé a trabajar con PostgreSQL porque «instalar» MySQL en mi Mac fue un parto…
Ok, seguimos. Lo primero es saber que diccionarios tenemos instalados en el servidor. Al menos en mi caso tengo soporte en Español:
sudo su - postgres
psql
\dF
Y ahora las funciones. Entonces, sigamos el ejemplo anterior:
SELECT TO_TSVECTOR('spanish', 'Luego que fue dado aviso a David, reunió a todo Israel, y cruzando el Jordán vino a ellos, y ordenó batalla contra ellos. Y cuando David hubo ordenado su tropa contra ellos, pelearon contra él los sirios.')
Importante el spanish como primer parámetro, ya que si no lo indicamos se considera el idioma Inglés.
Y esto qué es ? Es un arreglo «lexemas» ordenados alfabéticamente e indicando la posición de la palabra en el texto original. Avis, por ejemplo, está en la posición 5. Y por qué no tenemos Luego, que, fue, dado, a ? Porque son palabras que tienen poco significado. Conjunciones o artículos no se consideran para una búsqueda, por lo que se omiten.
Qué es un lexema ?
Parte que se mantiene invariable en todas las palabras de una misma familia; expresa el significado común a toda la familia y puede coincidir o no con una palabra entera.»el lexema de ‘pato’ es ‘pat-’»
Entonces, el lexema de aviso es avis, el de batalla es batall y así. Podemos, entonces buscar por avisaron, aviso y obtendríamos este texto. O por batallaron y lo mismo.
Si queremos saber de antemano el lexama de una palabra, podemos usar TS_DEBUG. Sigamos con aviso.
SELECT TS_DEBUG('spanish', 'aviso')
Obtenemos, entre otras cosas:
(asciiword,"Word, all ASCII",aviso,{spanish_stem},spanish_stem,{avis})
Si, por ejemplo, usamos niño, obviamos el ascii.
(word,"Word, all letters",niño,{spanish_stem},spanish_stem,{niñ})
Pero de igual forma obtenemos un lexema.
Ok, volvamos a lo que vinimos. Ahora, digamos que estamos buscando todos los versículos que tengan una referencia a «avisaron«. Ya tenemos el lexema (avis) y ahora tenemos que saber si se cumple o no la búsqueda. Para eso usamos la función to_tsquery. De esta forma:
SELECT TO_TSVECTOR('spanish', 'Luego que fue dado aviso a David, reunió a todo Israel, y cruzando el Jordán vino a ellos, y ordenó batalla contra ellos. Y cuando David hubo ordenado su tropa contra ellos, pelearon contra él los sirios.')
@@ TO_TSQUERY('spanish', 'avisaron');
-- LOS @@ SE USAN PARA CONECTAR
Obtenemos una t (true) o f (false) dependiendo.
Para lo de arriba obtenemos una t. Si comparamos con («montaña»), por decir algo… obtenemos una f.
Lo mismo podemos para buscar distintas palabras, unidas con un & para un Y o un | (pipe) para un O, un ! para negar. Incluso combinar, por ejemplo:
Todo perfecto! Si no fuera por el rendimiento, podrías simplemente correr:
SELECT * FROM montesanto.versiculo
WHERE TO_TSVECTOR('spanish', texto) @@ TO_TSQUERY('spanish', 'avisar');
En total, esa tabla tiene 31102 registros. La conexión fue a una BD en la nube, no local.
Entonces, cómo optimizamos el tema? Lo primero es agregar un campo en nuestra tabla, del tipo TSVECTOR:
No es necesario agregar un índice en esta columna, ya que el tipo de dato tsvectores un índice
Ahora sólo queda actualizar nuestra tabla. Es importante notar que la primera vez que se «llene» la columna será un proceso lento dependiendo del texto. Sin embargo no debería ejecutarse más de una vez, salvo que el texto se actualice. En mi caso, es un texto que no se modificará nunca más.
UPDATE montesanto.versiculo SET tokens_busqueda = TO_TSVECTOR('spanish', texto);
De 700 a 50
Todo bien! Pero aún no soluciono mi problema… porque si quiero buscar cruz, obtengo cruzando… para eso hubiera ocupado un LIKE.
Una última prueba entonces. Otra función útil es TS_RANK(vector, query). Como el nombre lo indica, le da un ranking a los resultados en base a criterios como la cercanía del término con el lexema, qué tantas veces se repite el término en un texto y así.
Entonces, veamos lo siguiente:
select
ts_rank(to_tsvector('spanish', 'Y Abner y los suyos caminaron por el Arabá toda aquella noche, y pasando el Jordán cruzaron por todo Bitrón y llegaron a Mahanaim.'),
to_tsquery('spanish','cruz')
) as spanish,
ts_rank(to_tsvector('Y Abner y los suyos caminaron por el Arabá toda aquella noche, y pasando el Jordán cruzaron por todo Bitrón y llegaron a Mahanaim.'),
to_tsquery('cruz')
) as nada
El ranking usando el diccionario en español y el por defecto. Aquí el corte lo hace «cruzaron«, si pregunto por «cruz«.
Y ahora por:
select
ts_rank(to_tsvector('spanish', 'Cuando salían, hallaron a un hombre de Cirene que se llamaba Simón; a éste obligaron a que llevase la cruz.'),
to_tsquery('spanish','cruz')
) as spanish,
ts_rank(to_tsvector('Cuando salían, hallaron a un hombre de Cirene que se llamaba Simón; a éste obligaron a que llevase la cruz.'),
to_tsquery('cruz')
) as nada
Epa! Aquí tenemos información relevante! Entonces puedo sumar ambos datos y ordenar por dicha suma:
select texto,
ts_rank(tokens_busqueda, to_tsquery('spanish','cruz')) + ts_rank(to_tsvector(texto), to_tsquery('cruz')) as ranking
from versiculo
where to_tsvector('spanish', texto) @@ to_tsquery('spanish','cruz')
order by ranking DESC
Y ahora si! Si bien sigo teniendo los resultados «parecidos», se van al fondo ya que no son relevantes.
Queda actualizar la tabla para agregar este segundo token y listoco!
Entonces digo que necesito todo lo que entre como formData se validará en base a la clase ArticuloFormData. Además, tengo un parámetro extra que se llama etiquetas. El resultado de la validación se quedará en binding y la info se queda en model. Nada raro.
Las reglas de validación son, entre otras cosas:
public class ArticuloFormData {
@NotNull(message = "El artículo debe tener un título")
@Size(min = 3, max = 255)
private String titulo;
@NotNull(message = "El artículo debe tener contenido")
@Size(min = 50, message = "El artículo debe tener al menos 50 caracteres")
private String texto;
//blablabla
}
De modo que si envío el formulario en blanco, debería caerse por esos 2 cosos y por lo tanto el controller me devolvería.
Error!
Tengo lo siguiente:
Whitelabel Error Page
This application has no explicit mapping for /error, so you are seeing this as a fallback.
Wed Dec 22 16:27:10 CLST 2021
There was an unexpected error (type=Bad Request, status=400).
Validation failed for object='formData'. Error count: 2
org.springframework.validation.BindException: org.springframework.validation.BeanPropertyBindingResult: 2 errors
Field error in object 'formData' on field 'titulo': rejected value []; codes [Size.formData.titulo,Size.titulo,Size.java.lang.String,Size]; arguments [org.springframework.context.support.DefaultMessageSourceResolvable: codes [formData.titulo,titulo]; arguments []; default message [titulo],255,3]; default message [el tamaño debe estar entre 3 y 255]
Field error in object 'formData' on field 'texto': rejected value []; codes [Size.formData.texto,Size.texto,Size.java.lang.String,Size]; arguments [org.springframework.context.support.DefaultMessageSourceResolvable: codes [formData.texto,texto]; arguments []; default message [texto],2147483647,50]; default message [El artículo debe tener al menos 50 caracteres]
at org.springframework.web.method.annotation.ModelAttributeMethodProcessor.resolveArgument(ModelAttributeMethodProcessor.java:175)
Y luego de darle mil vueltas, entendí que el orden de los parámetros en la función son importantes!!
Donde tengo:
public String nuevo(
@Valid @ModelAttribute("formData") ArticuloFormData formData,
@RequestParam String etiquetas,
BindingResult binding,
Model model){
}
Debería tener:
@PostMapping(value = "/Articulo/Nuevo")
public String nuevo(
@Valid @ModelAttribute("formData") ArticuloFormData formData,
BindingResult binding,
@RequestParam String etiquetas,
Model model){
}
Lo ves ? BindingResult debe ir si o si después de lo que quiero evaluar. En este caso formData.
Y ahora pruebo nuevamente:
Listo!
Me costó pillarlo, pero nunca leí que el orden fuera importante 😀
Esta es de esas entradas que escribo para mi mismo 😀
Asumiendo que tenemos nuestra app spring funcionando en local, ahora queremos subirla al servidor. En mi caso un VPS corriendo Debian 10.
Lo primero entonces es limpiar y compilar. Ojo que en mi caso es una aplicación funcionando «solita», por lo que construyo un .jar y no un .war
Ejecutan los comandos gradle o, en mi caso, con IntellijIDEA:
Con el .jar generado, lo subimos a nuestra carpeta. En mi caso:
/var/www/monteapp es la carpeta principal. /var/www/monteapp/build tiene el .jar final y el archivo de inicio. /var/www/monteapp/build/build tiene los archivos de versión en respaldo. El nombre no es el mejor, pero cuando estaba creando las carpetas me equivoqué y ya luego los dejé así 😀
Ok entonces ahora elimino el montesanto.jar (archivo «real») y lo reemplazo por el que acabo de subir.
Para probar, lo ejecuto con un:
java -jar montesanto.jar
Si todo funciona bien, inicio el servicio final.
Ahora, para el servicio final, primero leamos correMontesanto:
Donde lo importante, como ven, son las rutas. Ok ese archivo montesanto.service lo tengo bajo /etc/systemd/system/ y de esa forma puedo llamarlo directamente systemctl.
systemctl start montesanto.service
systemctl status montesanto.service
systemctl stop montesanto.service
Y así.
Por último, y como mi aplicación está corriendo en ip:8080, el reverse proxy de nginx para que entre directamente por un dominio (o subDominio).